Topic
How can we determine the popularity of a song/album given its features (duration, danceability, loudness, tempo, etc)?
Hypothesis
By training a machine learning model through various input features, we can predict the target variable, popularity. Popularity is on a scale between 0-100, with 100 being the most popular song.
Data Acquisition
We used the spotify tracks dataset found on Kaggle. The file contained 114,000 rows of different songs with 20 columns.
| track_id | artists | album_name | track_name | popularity | duration_ms | explicit | danceability | energy | key | loudness | mode | speechiness | acousticness | instrumentalness | liveness | valence | tempo | time_signature | track_genre |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5SuOikwiRyPMVoIQDJUgSV | Gen Hoshino | Comedy | Comedy | 73 | 230666 | False | 0.676 | 0.4610 | 1 | -6.746 | 0 | 0.1430 | 0.0322 | 0.000001 | 0.3580 | 0.715 | 87.917 | 4 | acoustic |
| 4qPNDBW1i3p13qLCt0Ki3A | Ben Woodward | Ghost (Acoustic) | Ghost - Acoustic | 55 | 149610 | False | 0.420 | 0.1660 | 1 | -17.235 | 1 | 0.0763 | 0.9240 | 0.000006 | 0.1010 | 0.267 | 77.489 | 4 | acoustic |
| 1iJBSr7s7jYXzM8EGcbK5b | Ingrid Michaelson;ZAYN | To Begin Again | To Begin Again | 57 | 210826 | False | 0.438 | 0.3590 | 0 | -9.734 | 1 | 0.0557 | 0.2100 | 0.000000 | 0.1170 | 0.120 | 76.332 | 4 | acoustic |
| 6lfxq3CG4xtTiEg7opyCyx | Kina Grannis | Crazy Rich Asians (Original Motion Picture Soundtrack) | Can't Help Falling In Love | 71 | 201933 | False | 0.266 | 0.0596 | 0 | -18.515 | 1 | 0.0363 | 0.9050 | 0.000071 | 0.1320 | 0.143 | 181.740 | 3 | acoustic |
| 5vjLSffimiIP26QG5WcN2K | Chord Overstreet | Hold On | Hold On | 82 | 198853 | False | 0.618 | 0.4430 | 2 | -9.681 | 1 | 0.0526 | 0.4690 | 0.000000 | 0.0829 | 0.167 | 119.949 | 4 | acoustic |
Data Preprocessing
After dropping columns that had minimal correlation to popularity, since most models only accepted numerical inputs, we created a pipeline to impute missing values and one hot encode categorical values. We ended up using 14 features (duration_ms, explicit, danceability, energy, key, loudness, mode, speechiness, acousticness, instrumentalness, liveness, valence, tempo, and time_signature) to create the machine learning model.
numerical_transformer = SimpleImputer(strategy='mean')
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
preprocessor = ColumnTransformer(
transformers=[
('num', numerical_transformer, numerical_cols),
('cat', categorical_transformer, categorical_cols)
])
Exploratory Data Analysis
Before running the model, we explored the dataset to gain deeper insights. We found that the average song popularity is 33.2, with a standard deviation (STD) of 22.3. This means that the popularity of songs in the file can widely differ from one another. Afterwards, we used various plots to explore the data further.
Histogram of song popularity:
Subplot of various audio features:
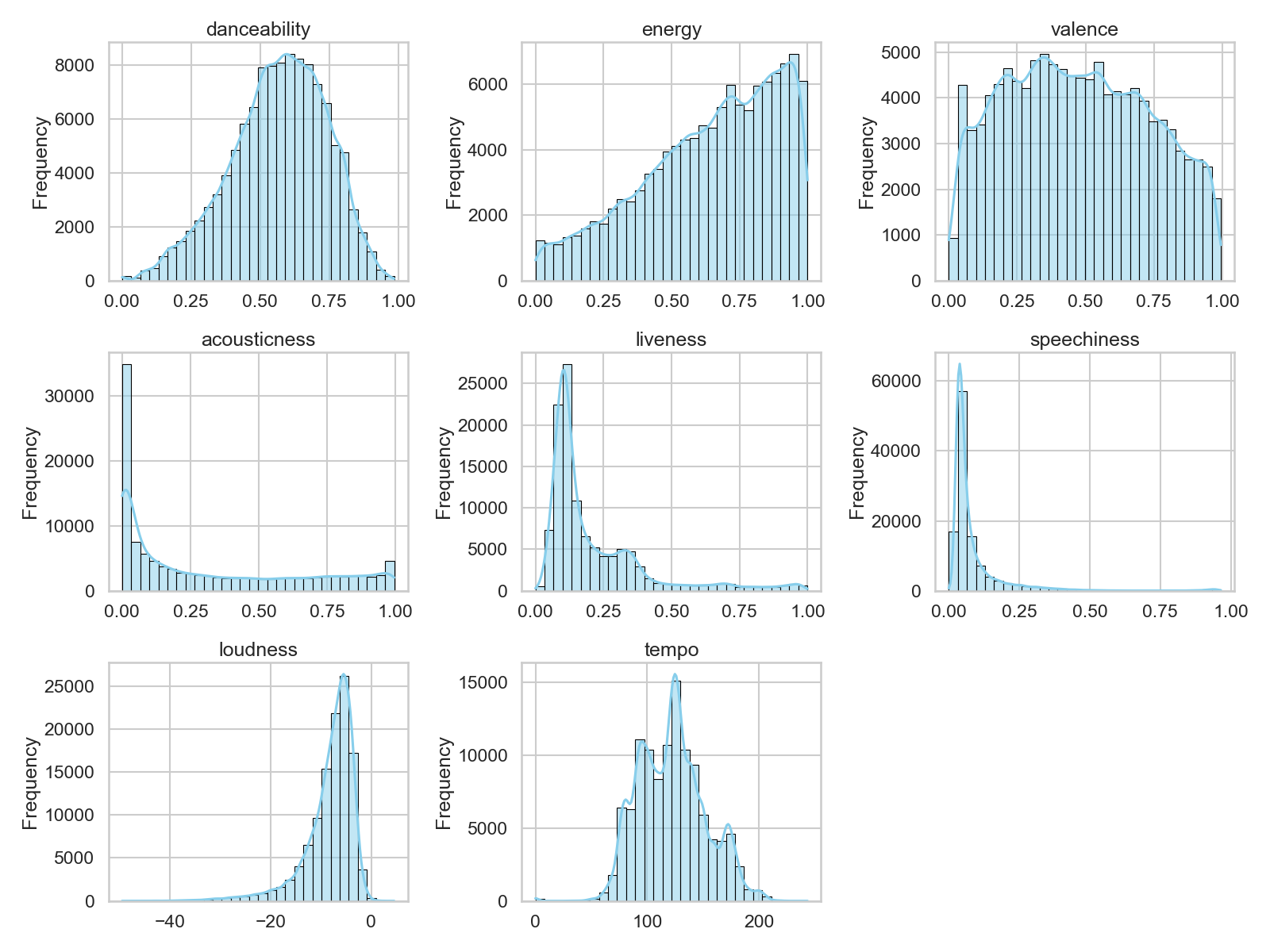
As seen in the histogram, many songs have a very low (0-4) popularity score. We first thought that the person who made the dataset assigned a popularity score of 0 to songs where the popularity data does not exist. However, after reading through the description of the dataset, we realized that popularity was calculated using a formula that focuses mainly on how many recent plays the songs had. From this, we deduced that these songs had a very low popularity value probably because they did not have a lot of recent streams, and not due to missing data. As a result, we chose to keep these songs in the dataset.
Data Modeling
We settled on using RandomForestRegressor as our machine learning model due to its simple parameters and general robustness with big datasets. After dropping the popularity column and setting it as the target variable, we then split the dataset into a training and testing dataset, putting 80% of the rows for training and 20% for validation. To avoid data leakage, we again used a pipeline to link the preprocessed data with the model. For our model, we used 100 trees and set random_state to 0 to ensure reproducibility.
model = RandomForestRegressor(n_estimators=100,
max_depth=None,
min_samples_split=2,
min_samples_leaf=1,
max_features='sqrt',
bootstrap=True,
random_state=0)
clf = Pipeline(steps=[('preprocessor', preprocessor),
('model', model)
])
clf.fit(X_train, y_train)
Data Validation
After fitting the model to the dataset, we used the testing dataset to evaluate our model performance. We found that the mean absolute error (MAE) of the model was 10.7. The produced MAE/STD ratio was 0.48, meaning that the model reduced the average error by around 52% compared to the strategy of guessing the mean popularity on every song. While the model is not particularly great at accurately predicting the popularity, it is still noticeably better than simply guessing the popularity. Since the MAE/STD ratio is under 0.5, it is still generally considered a good model.
preds = clf.predict(X_test)
print('MAE:', mean_absolute_error(y_test, preds))